The Aim:
When looking for a movie on Netlfix or IMDB.com to watch in the evening, most of the time one scrolls down very fast looking only at the name of the movie and looking at the picture provided. This project wants to tackle the question, whether it is possible to predict the genre of the movie by its name with the help of natural language processing algorithms.
Why predicting genre from a movie title is helpful? Before we see a movie we have ceratin expectations and genres help to form these ideas. If they are not fulfilled, perciever might fill frustrated, and therefore I propose that it is quite important how studios and independent movie makers name their movies.
The other part of project is focused on individual perceiver. According to user's rating of each movie the recommendation code will provide an alternative movies from the list with similar features. The project also focuses on detailed exploratory data analysis to answer some questions like:
When looking for a movie on Netlfix or IMDB.com to watch in the evening, most of the time one scrolls down very fast looking only at the name of the movie and looking at the picture provided. This project wants to tackle the question, whether it is possible to predict the genre of the movie by its name with the help of natural language processing algorithms.
Why predicting genre from a movie title is helpful? Before we see a movie we have ceratin expectations and genres help to form these ideas. If they are not fulfilled, perciever might fill frustrated, and therefore I propose that it is quite important how studios and independent movie makers name their movies.
The other part of project is focused on individual perceiver. According to user's rating of each movie the recommendation code will provide an alternative movies from the list with similar features. The project also focuses on detailed exploratory data analysis to answer some questions like:
- What are the most rated movies in the data set?
- What words are mostly used in titles for various genres?
- How many movies are there per genre?
- What is the distribution of movies per years?
- What are ratings distributions for each genre? And others...
The Data:
The dataset describes 5-star rating and free-text tagging activity from MovieLens, a movie recommendation service. It contains 24404096 ratings and 668953 tag applications across 40110 movies. These data were created by 259137 users between January 09, 1995 and October 17, 2016. This dataset was generated on October 18, 2016.
Users were selected at random for inclusion. All selected users had rated at least 1 movies. No demographic information is included. Each user is represented by an id, and no other information is provided.
The data are contained in the files genome-scores.csv, genome-tags.csv, links.csv, movies.csv, ratings.csv and tags.csv.
Ratings Data File Structure (ratings.csv)All ratings are contained in the file ratings.csv. Each line of this file after the header row represents one rating of one movie by one user, and has the following format:
Genres:
The dataset describes 5-star rating and free-text tagging activity from MovieLens, a movie recommendation service. It contains 24404096 ratings and 668953 tag applications across 40110 movies. These data were created by 259137 users between January 09, 1995 and October 17, 2016. This dataset was generated on October 18, 2016.
Users were selected at random for inclusion. All selected users had rated at least 1 movies. No demographic information is included. Each user is represented by an id, and no other information is provided.
The data are contained in the files genome-scores.csv, genome-tags.csv, links.csv, movies.csv, ratings.csv and tags.csv.
Ratings Data File Structure (ratings.csv)All ratings are contained in the file ratings.csv. Each line of this file after the header row represents one rating of one movie by one user, and has the following format:
- userId : Unique user ID
- movieId: Unique movie ID
- rating: Rating of a movie by user
- timestamp: Timestamps represent seconds since midnight Coordinated Universal Time (UTC) of January 1, 1970
- userId: Unique user ID
- movieId: Unique movie ID
- tag: User-generated metadata about movies
- timestamp: Timestamps represent seconds since midnight Coordinated Universal Time (UTC) of January 1, 1970
- movieId: Unique movie ID
- title: Title of a movie
- genres: Genre(s) of a movie
Genres:
- Action
- Adventure
- Animation
- Children's
- Comedy
- Crime
- Documentary
- Drama
- Fantasy
- Film-Noir
- Horror
- Musical
- Mystery
- Romance
- Sci-Fi
- Thriller
- War
- Western
- movieId: Unique movie ID
- imdbId: IMDB.com movie ID
- tmdbId: themoviedb.com movie ID
Exploratory Data Analysis
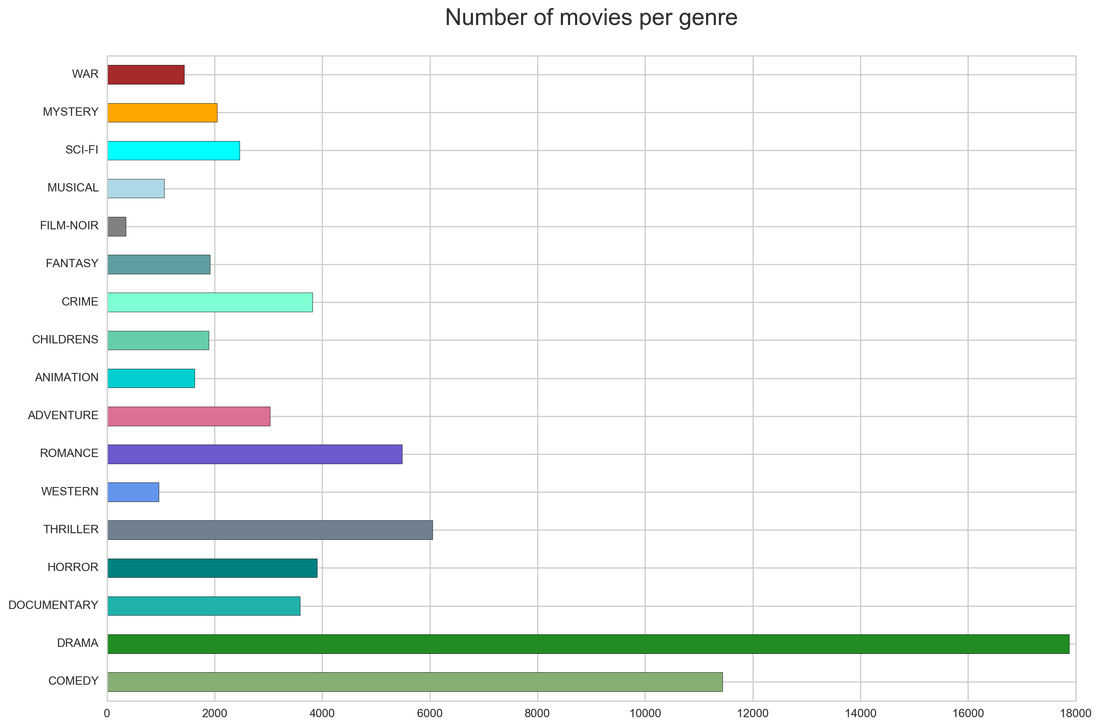
Exploring the dataset, first I looked at the spread of individual genres across the dataset (40110 movies).
Most of the movies are describe as drama, and comedy is the second most represented genres. There is a small number of film-noir movies. From this we can assume that the genre classification will mostly favor drama and comedy with very low predictions for film-noir and western.
Most of the movies are describe as drama, and comedy is the second most represented genres. There is a small number of film-noir movies. From this we can assume that the genre classification will mostly favor drama and comedy with very low predictions for film-noir and western.
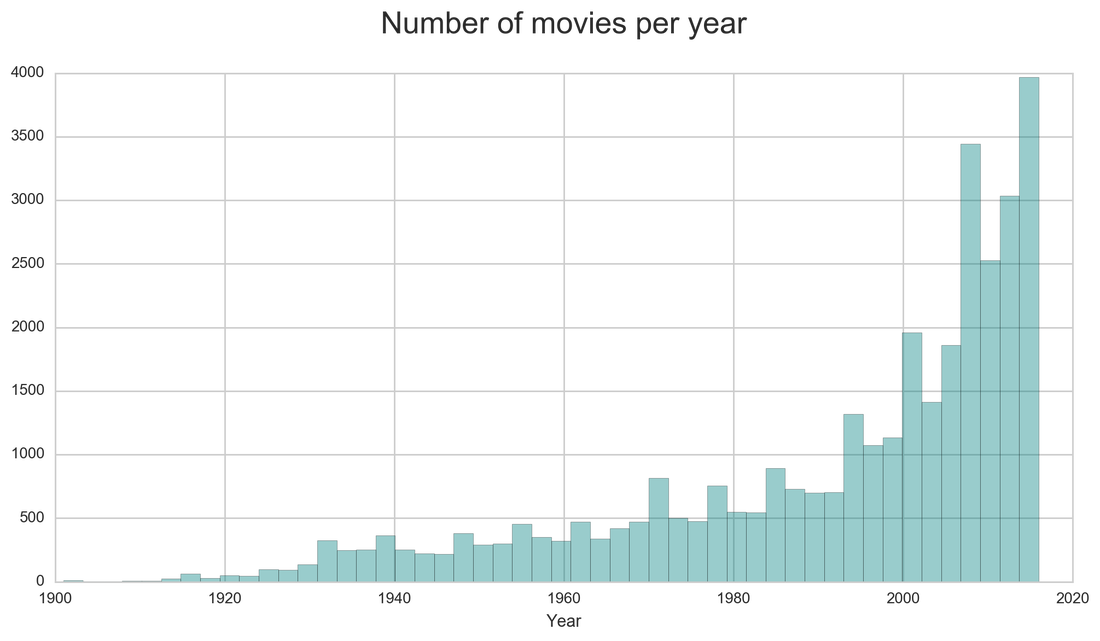
The next exploration looks at the distribution of the movie during the years. We can see that most of the movies are from the latest years.
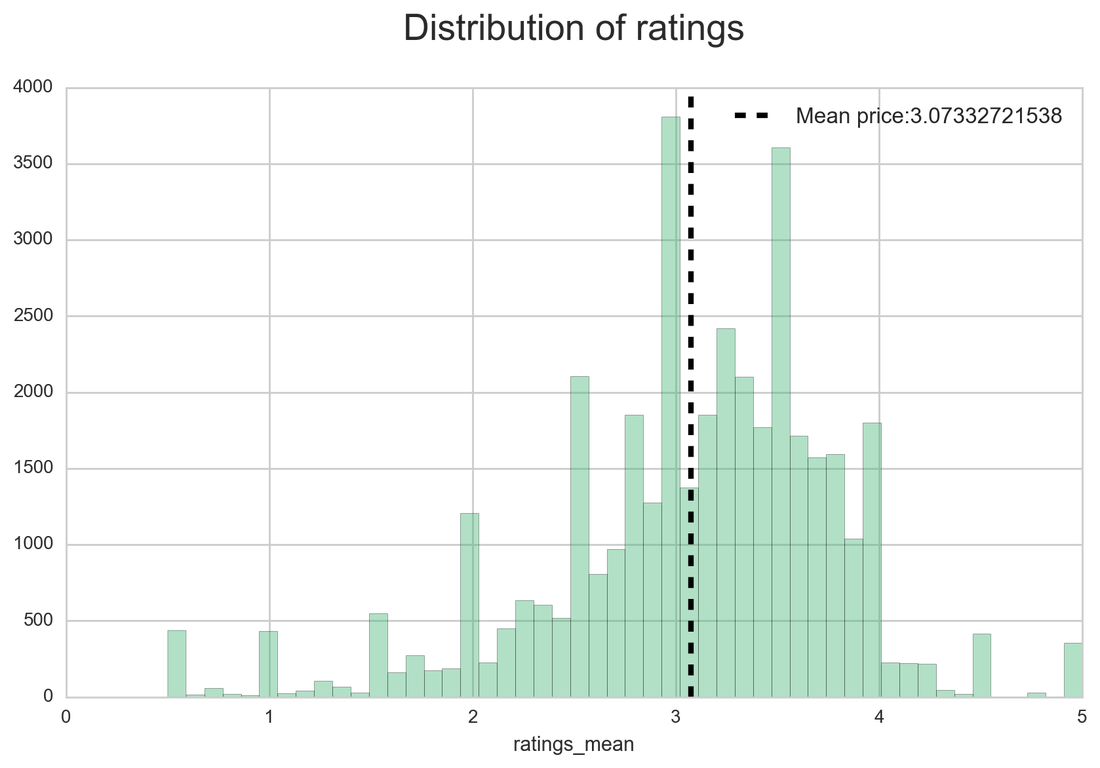
The datasets available also have ratings. The next plot is looking at the distribution of mean ratings (from many users) for each movie. The mean is above the middle value as the ratings were done according to the following scale:
0 - the worst
5 - the best
We can see that users are rating movies higher than the middle value 2.5. Later, we will look at ratings for each genre.
0 - the worst
5 - the best
We can see that users are rating movies higher than the middle value 2.5. Later, we will look at ratings for each genre.
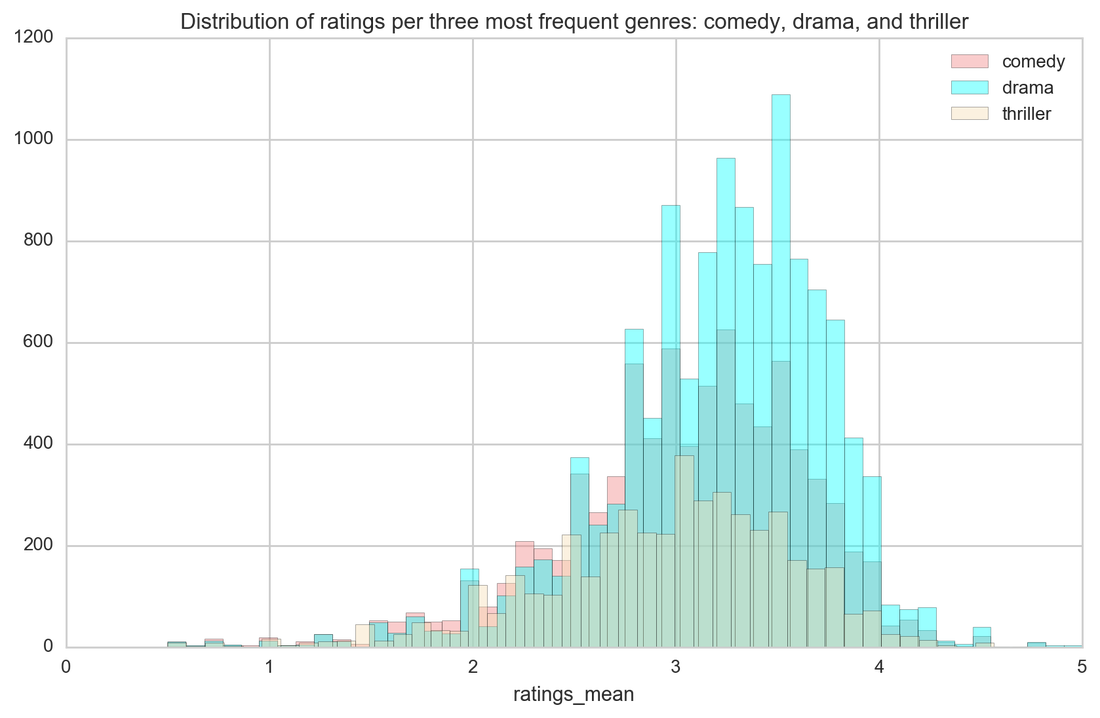
And now is the time for particular genres and their ratings. Horror is just a horror as this genre has the lowest ratings. Other genres are not significantly distinct when it comes to ratings (and I had high hopes for westerns!)
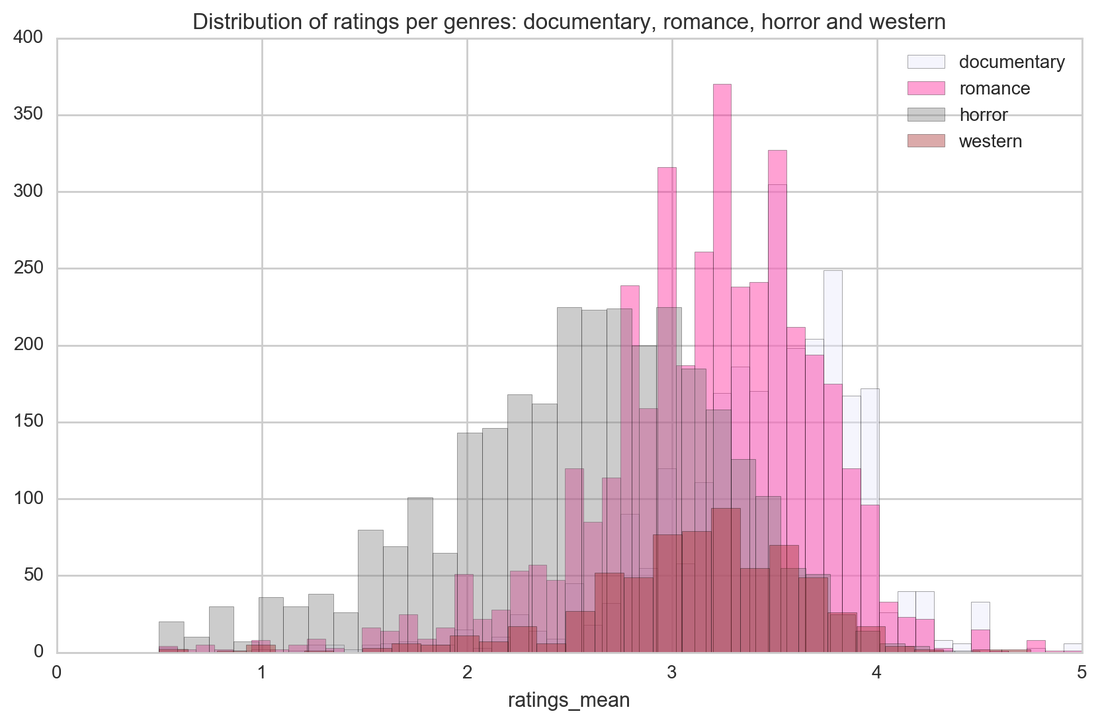
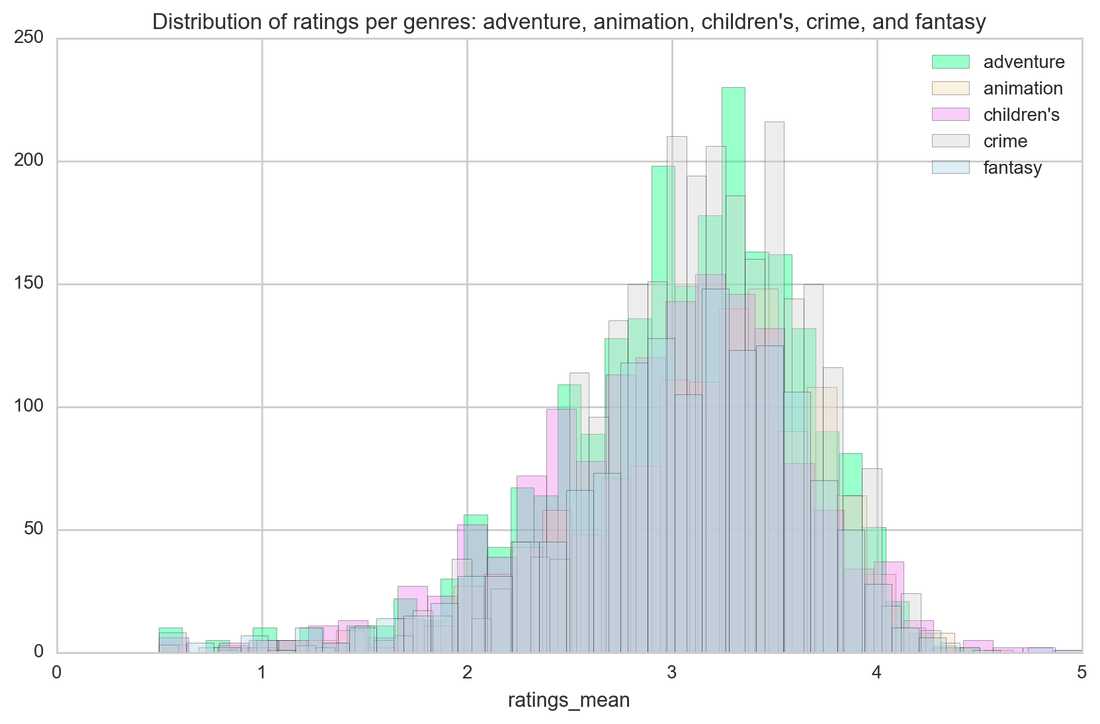
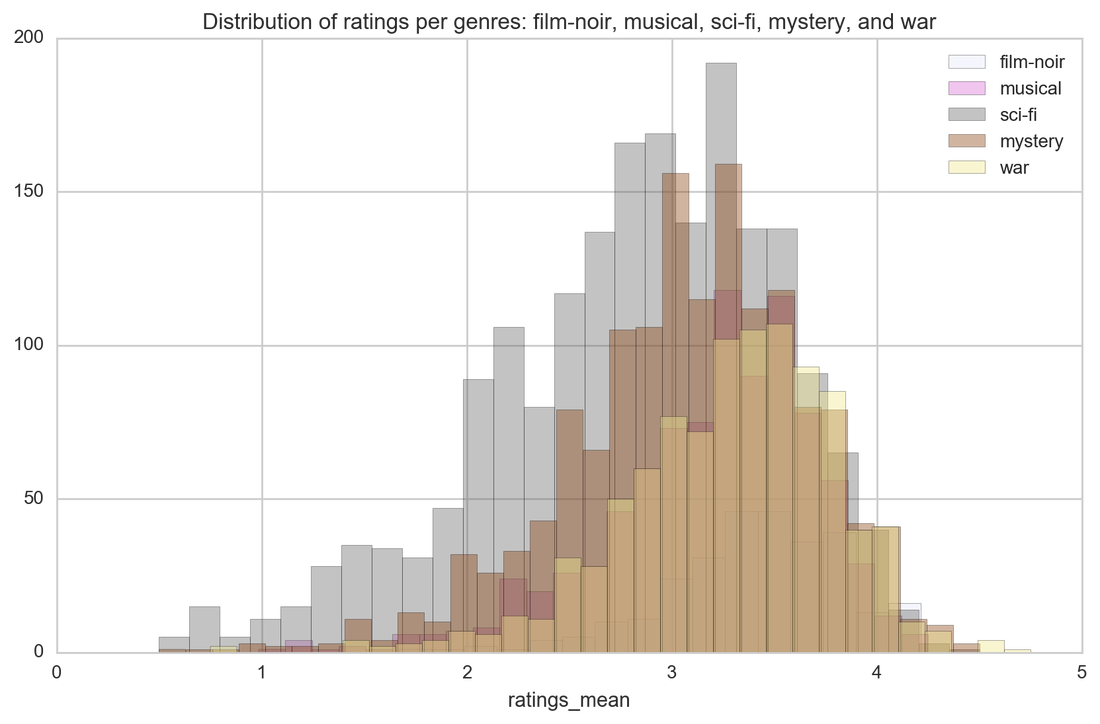
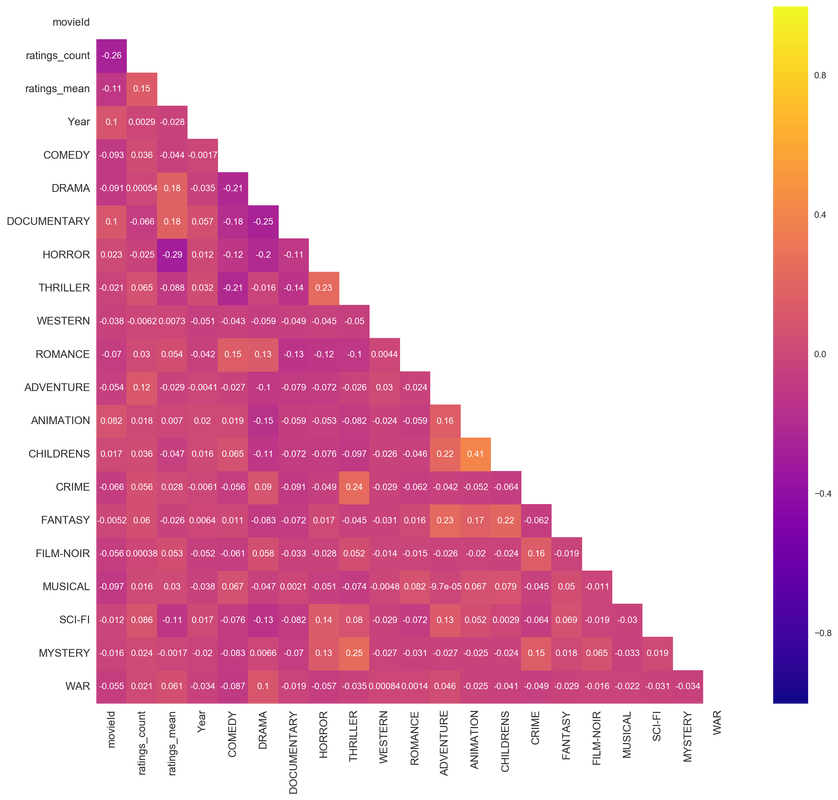
When it comes to genres classification, it is quite hard to predict as movies are usually categorized by more than one genre. Correlation heat map shows what genres are correlated as those will be the hardest to predict - the distinction between them is very slight.
We can see that children's movies are very highly correlated with animation, thriller with crime, thriller with mystery, fantasy with adventure, and fantasy with children's. Horror is most negatively correlated with mean ratings. With those correlated genres we can expect that the prediction of genre from movie's title will be especially problematic as they have much in common.
We can see that children's movies are very highly correlated with animation, thriller with crime, thriller with mystery, fantasy with adventure, and fantasy with children's. Horror is most negatively correlated with mean ratings. With those correlated genres we can expect that the prediction of genre from movie's title will be especially problematic as they have much in common.
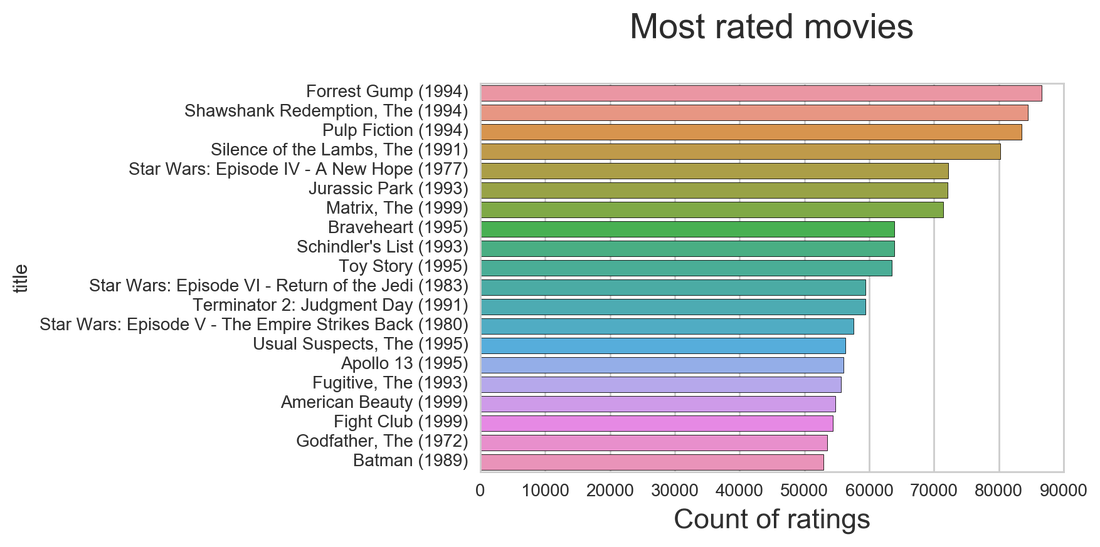
Three movies were rated more than 80k times! Below is a graph showing the most times rated movies, we can also assume that they are the most known and watched. Who knew that the 90's were so productive when it comes to most rated movies.
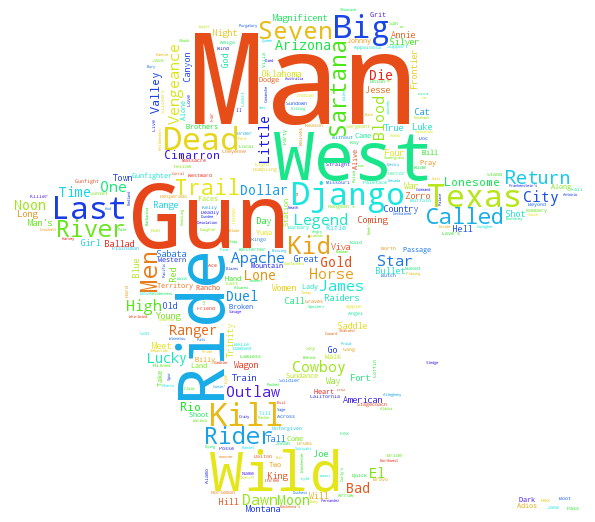
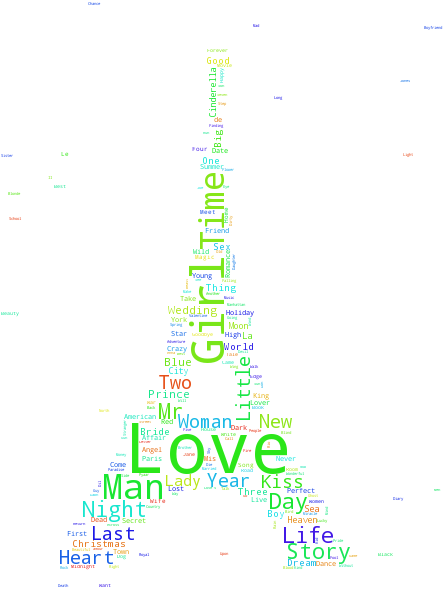
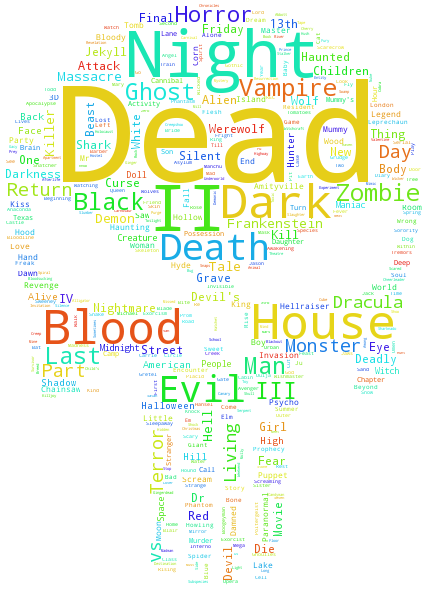
Before trying to predict the genres from titles, lets look at some infographics about what words are most frequently represented in the titles of particular genres. My favorite graphics are word clouds. I took only romance, horror, and western, but later I will have plot for all genres. I also used picture masks for the word clouds, so I will not give you a hint what genres is which cloud. You will know.
TF-IDF or term frequency - inverse document frequency is a method that counts the how many times a word appears in a title (in this case) and then adjusts it downward based on how many times that word appears across all titles in the dataset. This give more weights to words that are common in a title but not common across titles. This helps to highlight what is both important and unique about a title.
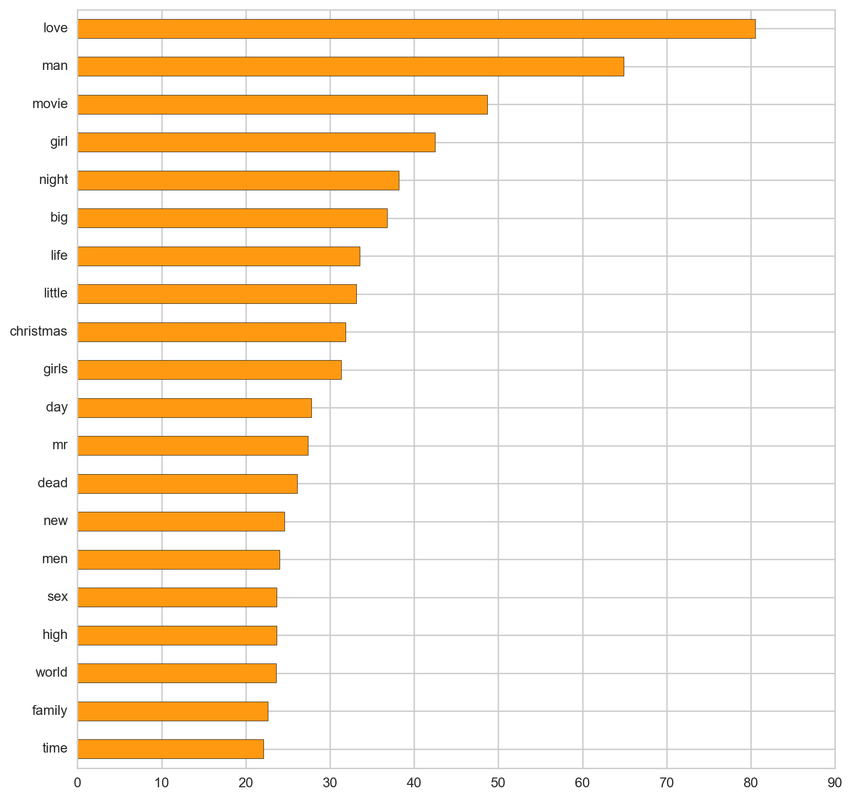
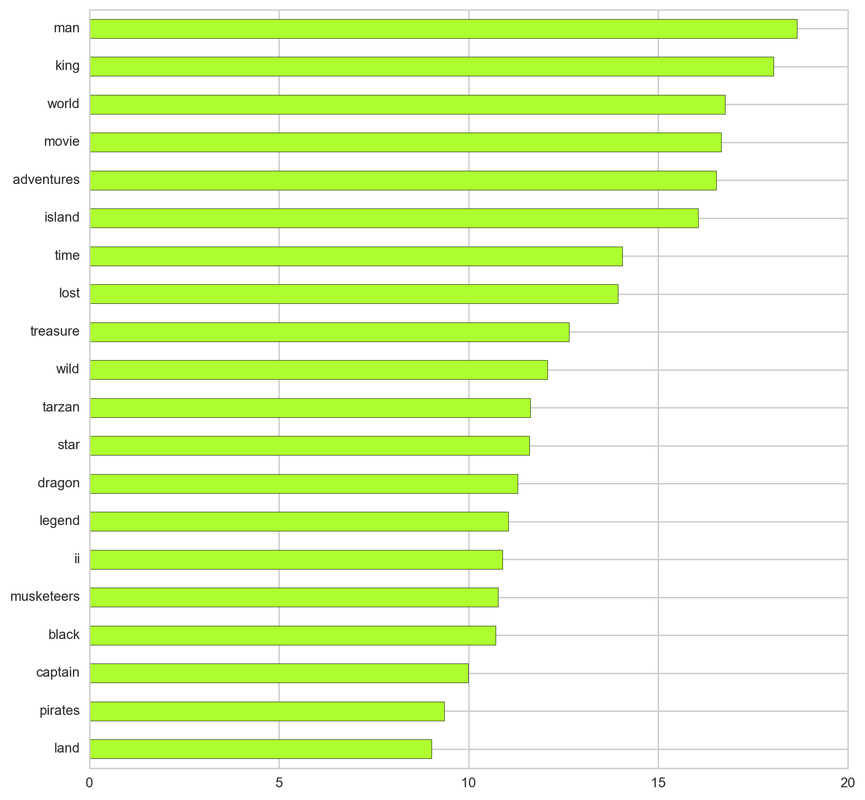
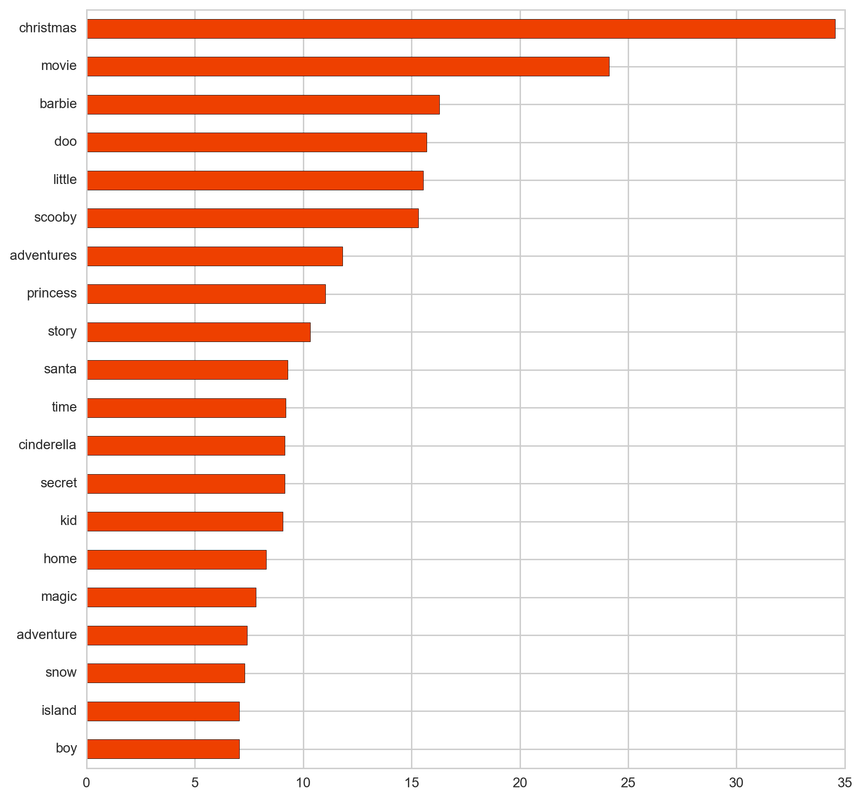
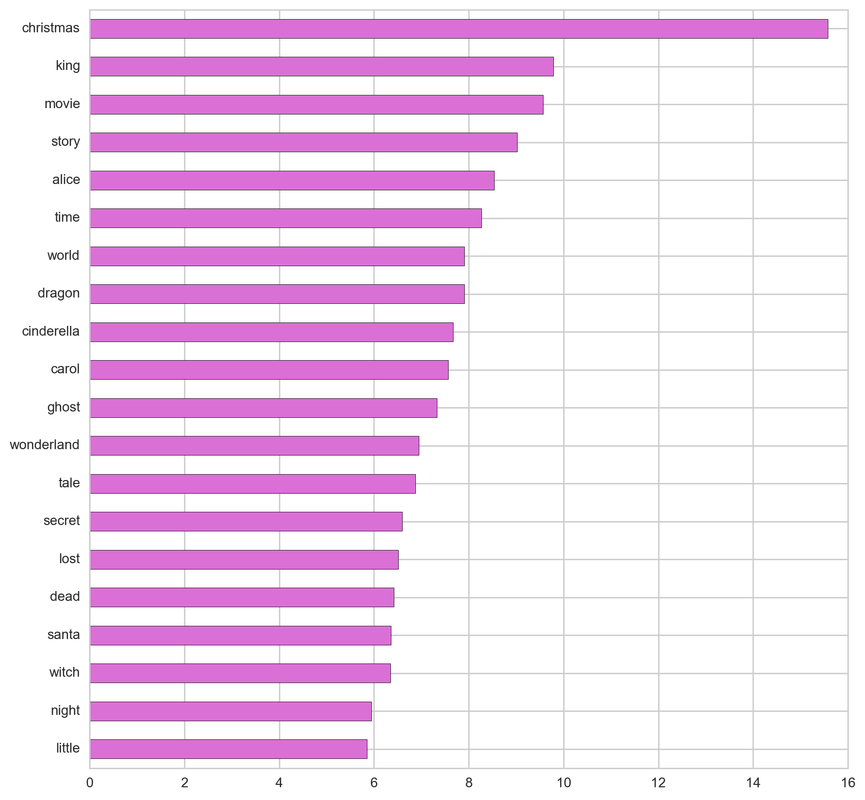
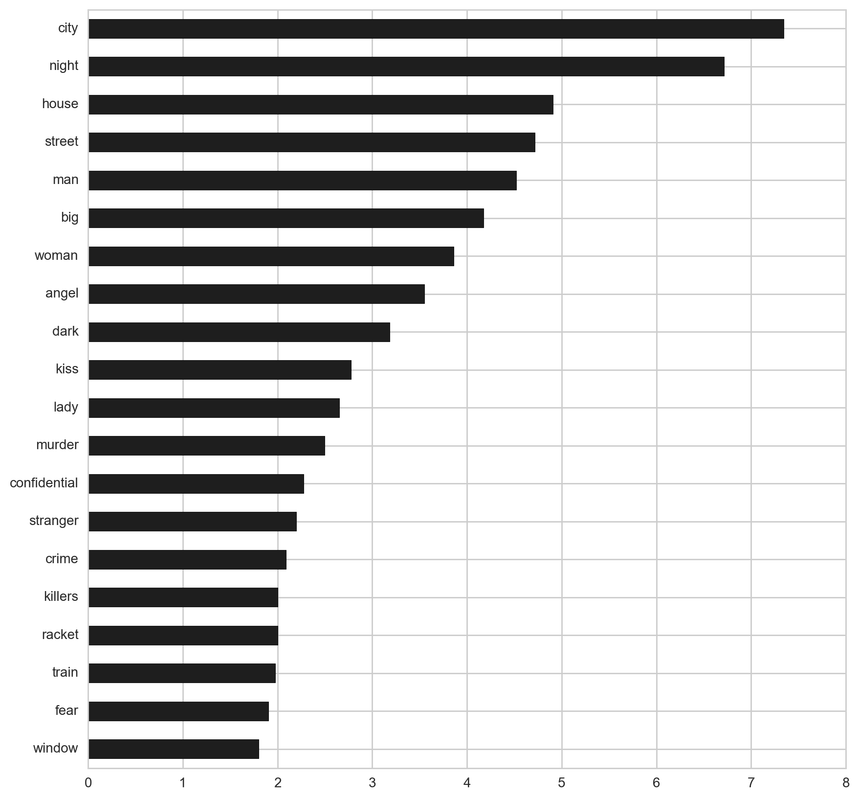
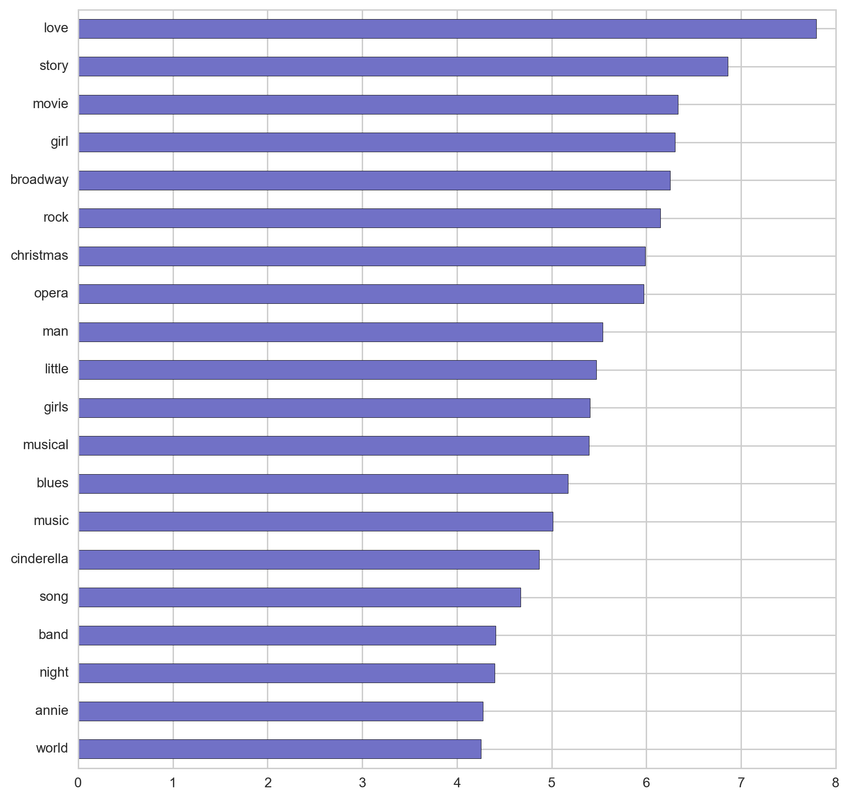
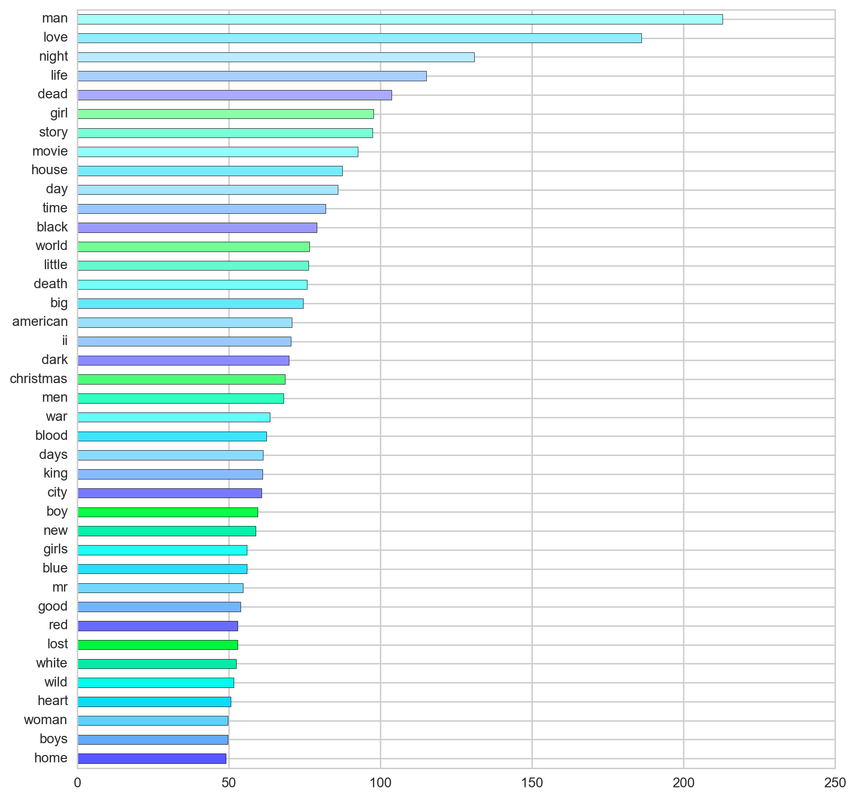
From the below tf-idf plots we can infer, which words will be important in predicting genres from titles. For example in war there are words like 'war', 'battle', 'soldiers', in mystery 'murder' and 'man', in sci-fi 'space' and 'planet, in 'love' and 'story', in film-noir 'city' and 'night', in 'christmas' and 'king', in crime 'man' and 'murder', in children's 'barbie' and 'princess', in animation 'pokemon' and 'mickey', in adventure 'treasure' and 'island', in drama 'love' and 'man', in western 'west' and 'gun', in documentary 'story' and 'life', in thriller 'dark' and 'black', in horror 'dead' and 'vampire', in comedy 'love' and 'man', and in romance 'love' and 'girl'.
From the below tf-idf plots we can infer, which words will be important in predicting genres from titles. For example in war there are words like 'war', 'battle', 'soldiers', in mystery 'murder' and 'man', in sci-fi 'space' and 'planet, in 'love' and 'story', in film-noir 'city' and 'night', in 'christmas' and 'king', in crime 'man' and 'murder', in children's 'barbie' and 'princess', in animation 'pokemon' and 'mickey', in adventure 'treasure' and 'island', in drama 'love' and 'man', in western 'west' and 'gun', in documentary 'story' and 'life', in thriller 'dark' and 'black', in horror 'dead' and 'vampire', in comedy 'love' and 'man', and in romance 'love' and 'girl'.
Romance:
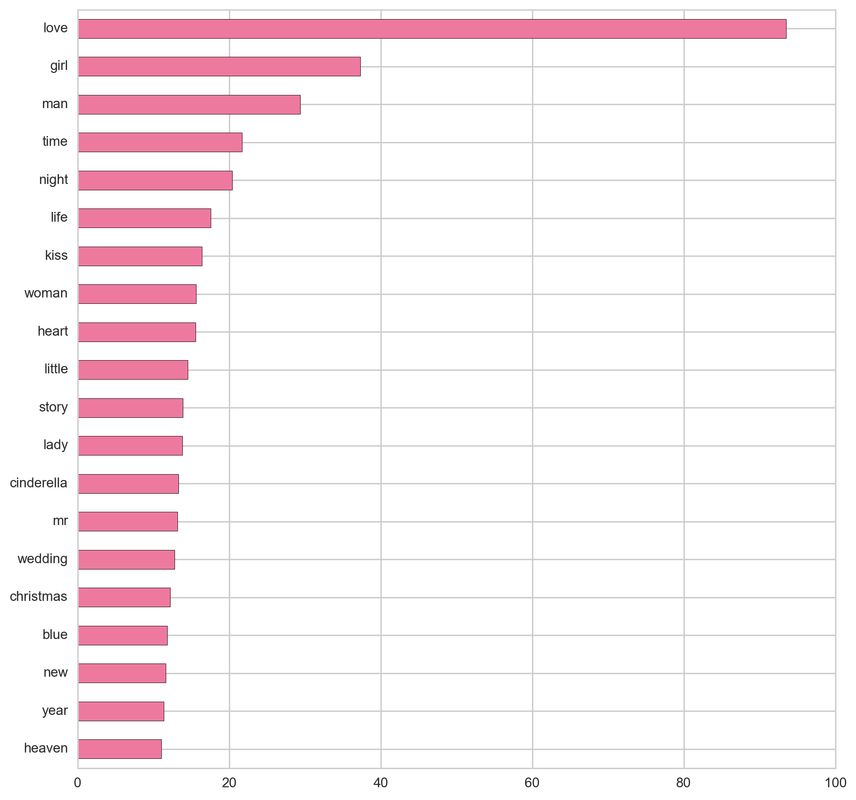
Horror:
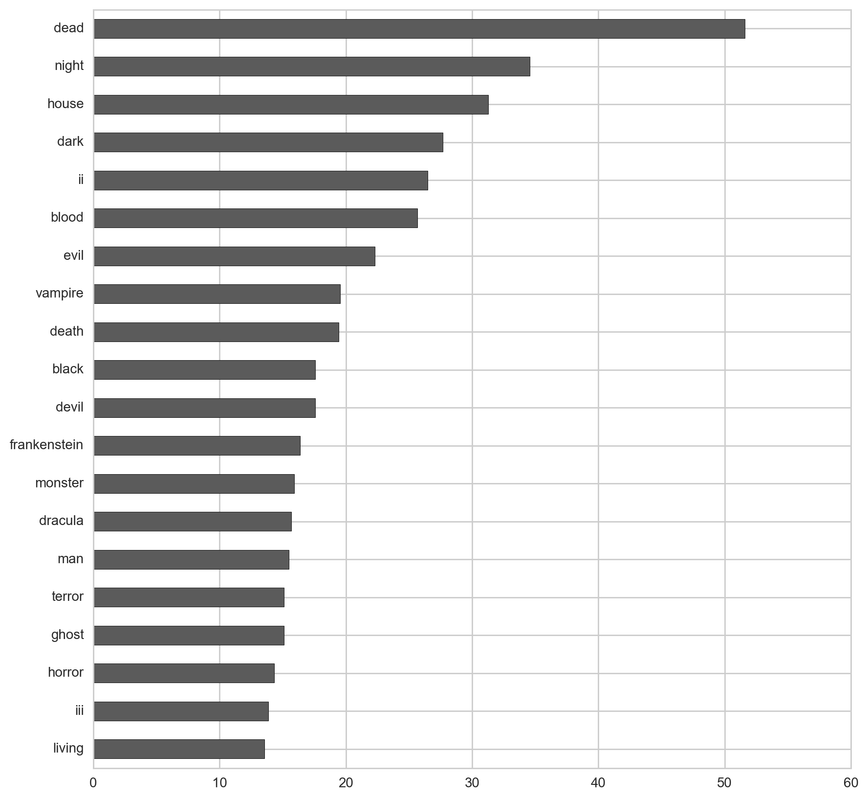
Western:
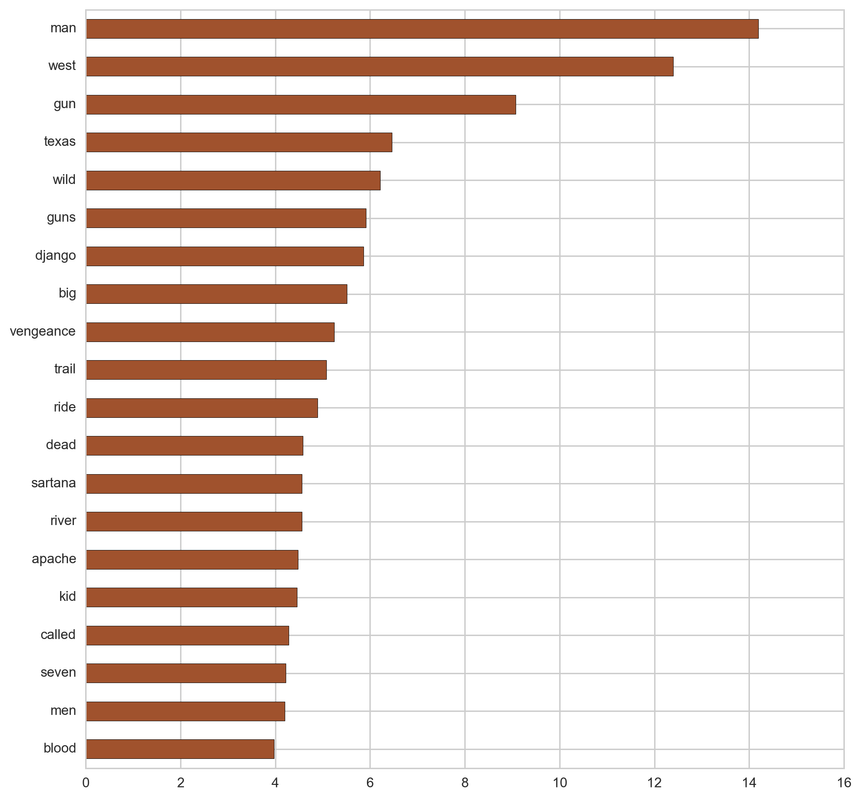
Thriller:
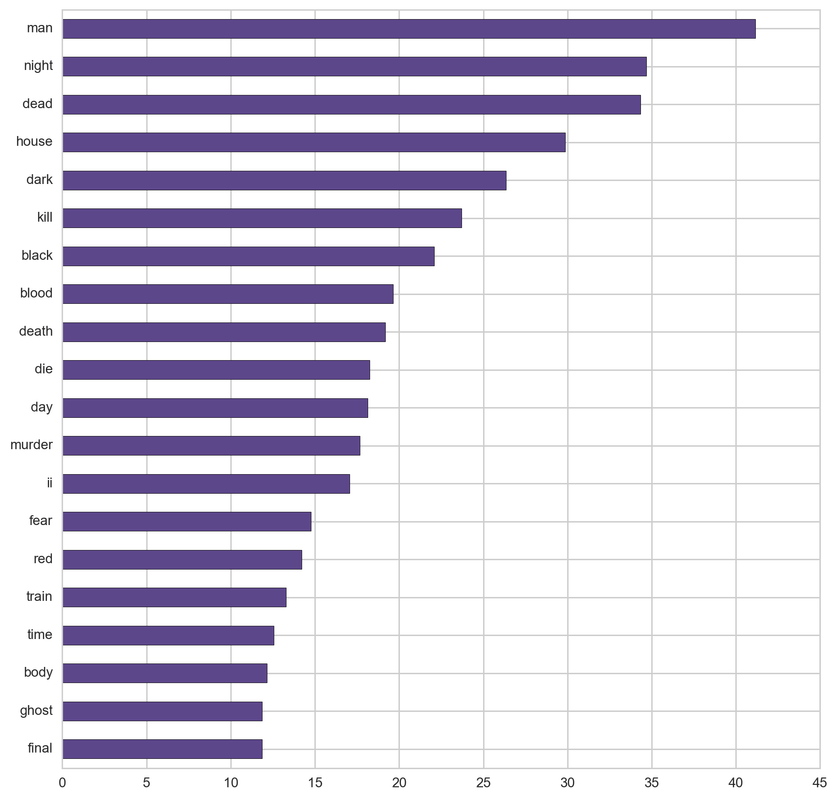
Sci-fi:
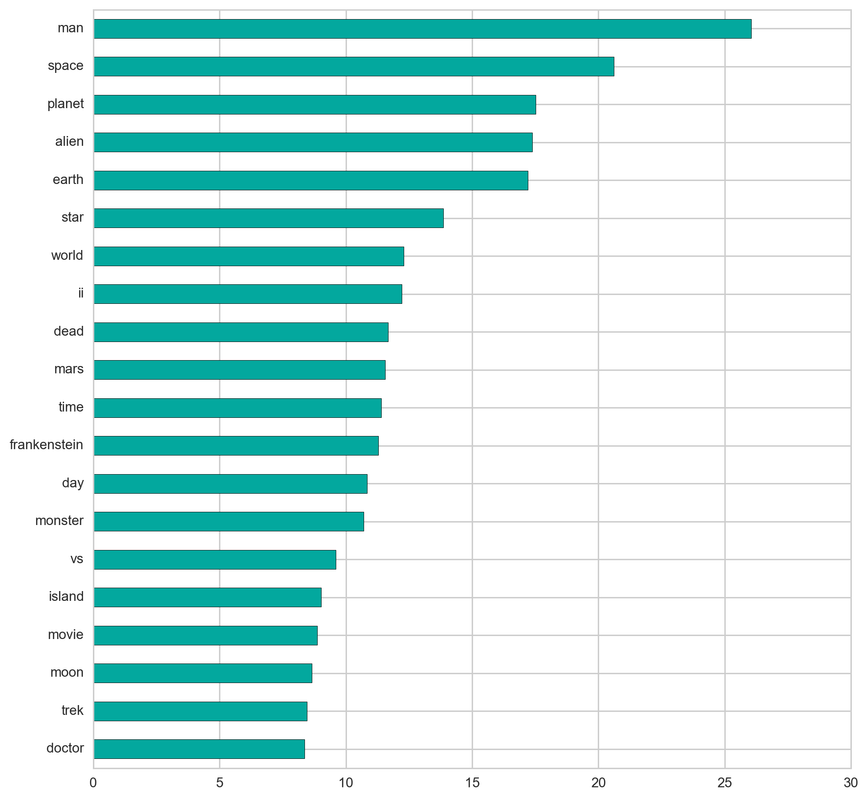
Comedy:
Adventure:
Children's:
Animation:
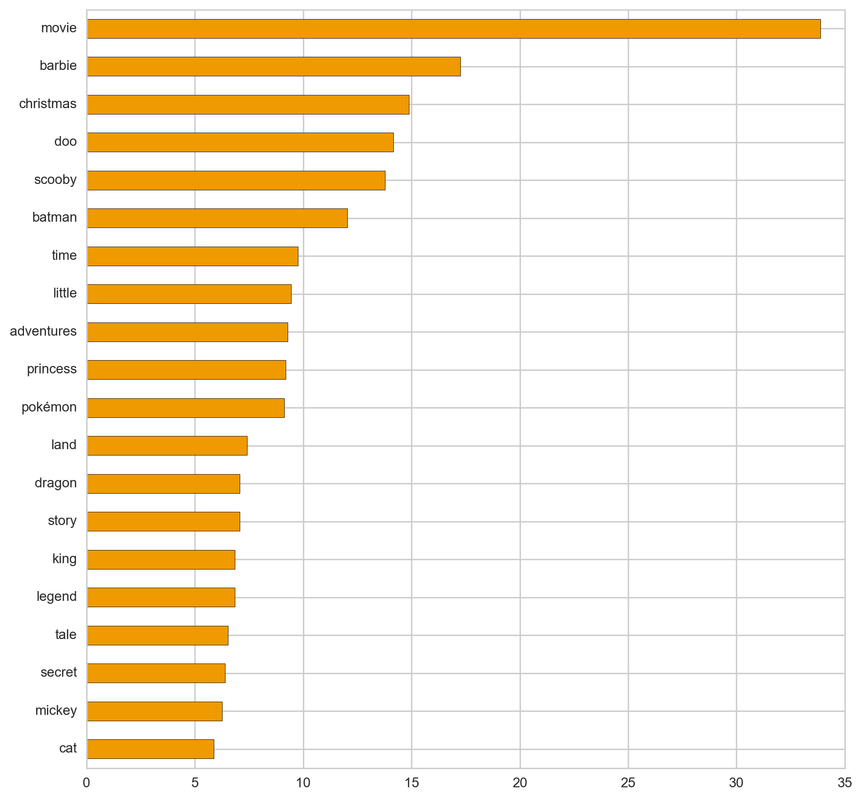
Drama:
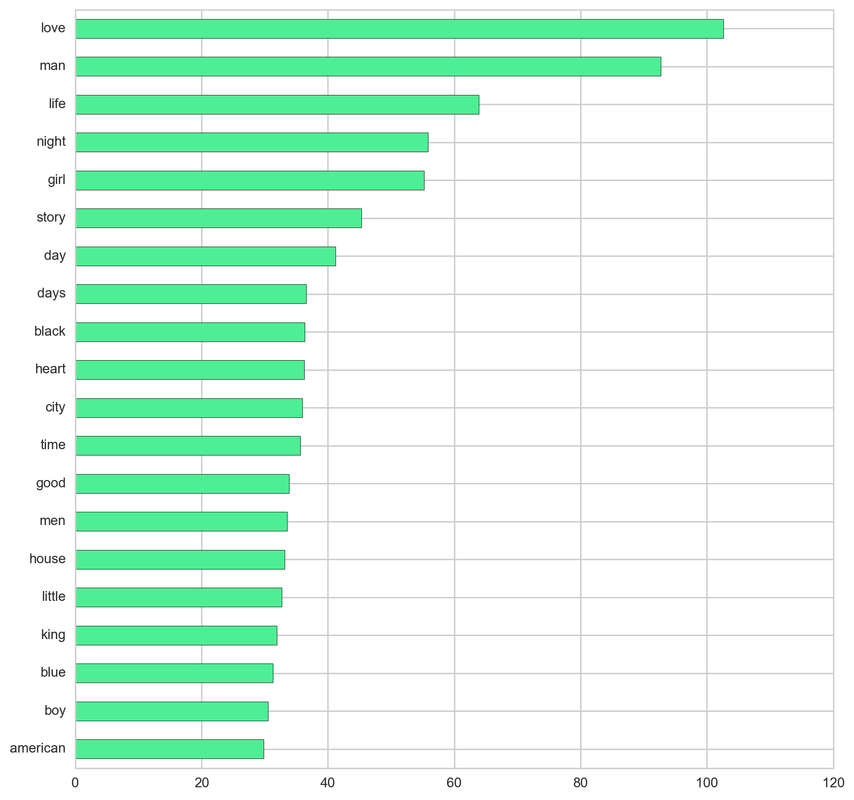
Documentary:
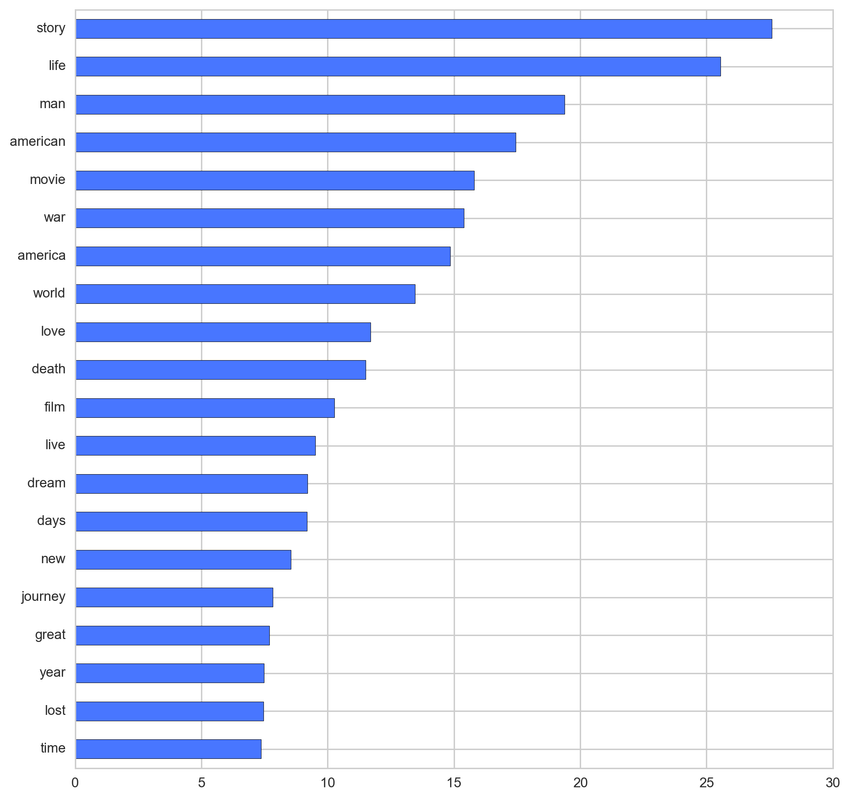
Mystery:
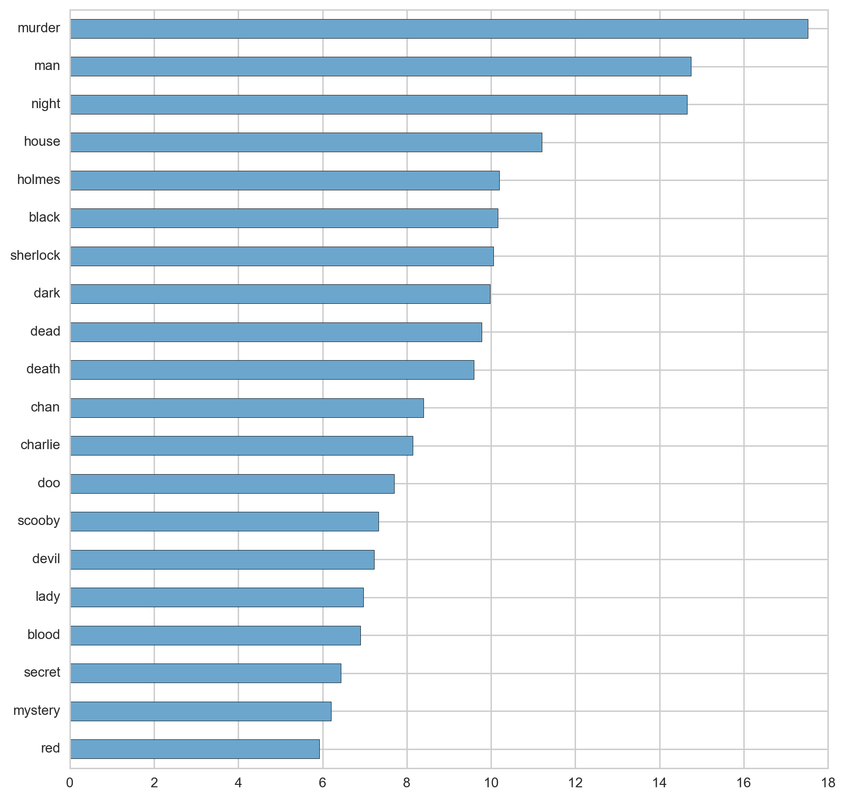
Crime:
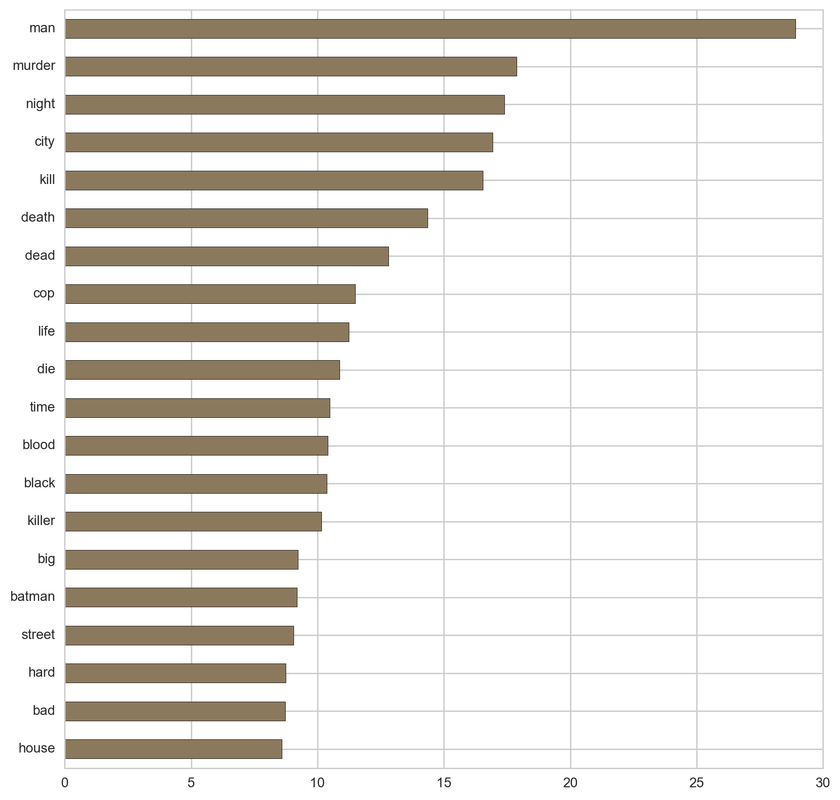
Fantasy:
Film-noir:
Musical:
War:
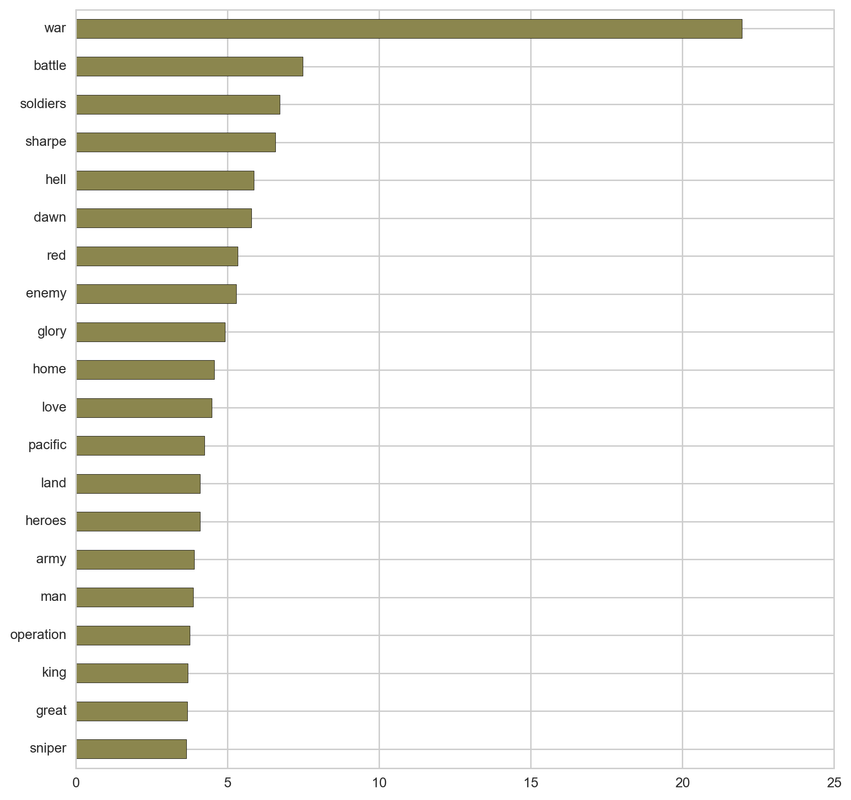
Overall (for all genres):
Genre prediction - One Versus Rest Classifier:
Movies usually fall into more than one genre, therefore classical classification would not be able to perform this task. I had to use multilabel classification. Multilabel classification assigns to each sample a set of target labels, it assumes that the features are not mutually exclusive such as movies genres.
First, I had to use Multi Label Binarizer to preprocess the data into a binirized format, so the model could process the labels. This transformer converts between strings based label format and the supported binarized multilabel format. It created a binary matrix that represents the class label.
I set up a pipeline that consists of the NLP feature extractions Count Vectorizer that transforms a collection of movie titles to a matrix of token counts and also Tfidf Transformer, which creates a tf-idf representation from a count matrix(Count Vectorizer). Tf-idf means term-frequency times inverse document-frequency. Tf-idf is better than using only term frequency as it downgrades the impact of tokens that are represented very frequently in titles, and therefore they provide less information than tokens that occur less frequently in the training set.
One-vs-rest strategy, that is executed by OneVsRestClassifier, fits one classifier per class. It associates a set of positive examples for a given class and a set of negative examples which represent all the other classes. It is computationally very efficient as it needs only the number of classifiers as the number of classes, and this also gives and insight into the class by exploring its classifier. Sklearn states: 'This is the most commonly used strategy and is a fair default choice.'Within the OneVsRest I used Linear Support Vector Classification as it is supported by OneVsRest and it separates the class according to state space positions by estimating the dividing hyperplane.
Movies usually fall into more than one genre, therefore classical classification would not be able to perform this task. I had to use multilabel classification. Multilabel classification assigns to each sample a set of target labels, it assumes that the features are not mutually exclusive such as movies genres.
First, I had to use Multi Label Binarizer to preprocess the data into a binirized format, so the model could process the labels. This transformer converts between strings based label format and the supported binarized multilabel format. It created a binary matrix that represents the class label.
I set up a pipeline that consists of the NLP feature extractions Count Vectorizer that transforms a collection of movie titles to a matrix of token counts and also Tfidf Transformer, which creates a tf-idf representation from a count matrix(Count Vectorizer). Tf-idf means term-frequency times inverse document-frequency. Tf-idf is better than using only term frequency as it downgrades the impact of tokens that are represented very frequently in titles, and therefore they provide less information than tokens that occur less frequently in the training set.
One-vs-rest strategy, that is executed by OneVsRestClassifier, fits one classifier per class. It associates a set of positive examples for a given class and a set of negative examples which represent all the other classes. It is computationally very efficient as it needs only the number of classifiers as the number of classes, and this also gives and insight into the class by exploring its classifier. Sklearn states: 'This is the most commonly used strategy and is a fair default choice.'Within the OneVsRest I used Linear Support Vector Classification as it is supported by OneVsRest and it separates the class according to state space positions by estimating the dividing hyperplane.
So how the model performed?
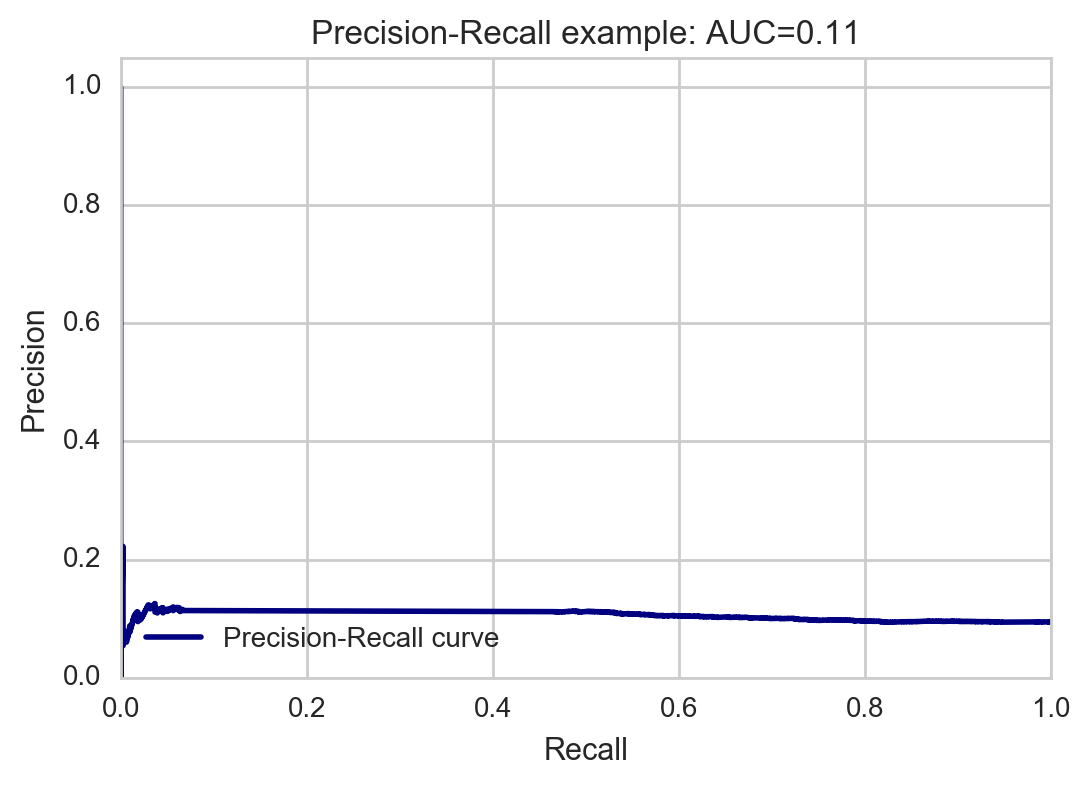
The precision/recall cure shows us the trade-off between precision (false positive rate) and recall (false negative rate). High scores for both show that the classifier is returning accurate results (high precision), as well as returning a majority of all positive results (high recall). Accuracy 11% does not seem very good, but in multi-label classification, this function computes subset accuracy: the set of labels predicted for a sample must exactly match the corresponding set of labels in y_true, so it is quite harsh.
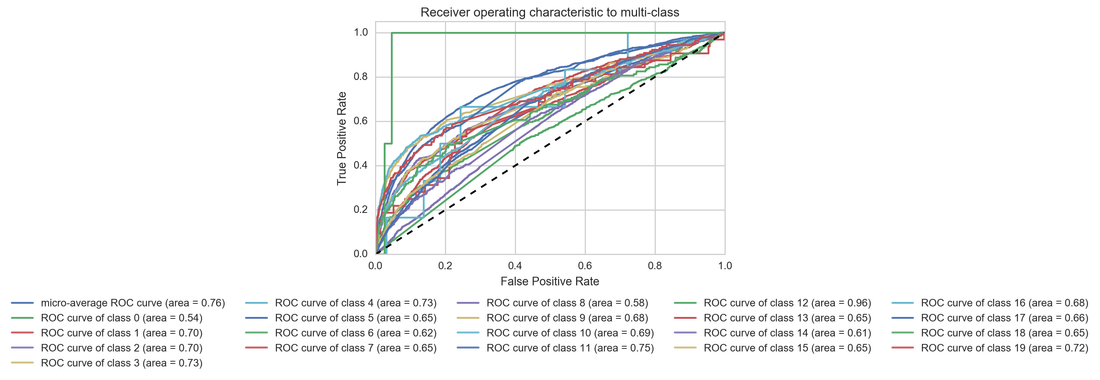
(0, '(no genres listed)')
(1, 'action')
(2, 'adventure')
(3, 'animation')
(4, 'children')
(5, 'comedy')
(6, 'crime')
(7, 'documentary')
(8, 'drama')
(9, 'fantasy')
(10, 'film-noir')
(11, 'horror')
(12, 'imax')
(13, 'musical')
(14, 'mystery')
(15, 'romance')
(16, 'sci-fi')
(17, 'thriller')
(18, 'war')
(19, 'western')
Receiving Operating Characteristic, or ROC, is a visual way for inspecting the performance of a binary classifier (0/1). In particular, it's comparing the rate at which the classifier is making correct predictions: True Positives and the rate at which the classifier is making false alarms: (False Positives or FP). Some of the genres are doing pretty bad and some of them are doing better. The best is horror with area under the curve (AUC) 0.75. On the other hand the worst is doing drama with AUC 0.58.
I also looked at the at least one genre correctly predicted. In this case the model was right in 41% of cases.
Recommendation System:
For the recommendation system I used again Tfidf vectorizer as it returns the proportion that each token is represented in the collection of movie tags and genres. Then I computed the cosine similarity between the user's movie and the rest of of the movies (genres, tags, and mean ratings). In Sklearn cosine similarity, or the cosine kernel, processes similarity as the normalized dot product of features and target. Cosine similarity computes the cosine of the angle between the two vectors. The cosine of 0° is 1, and it is less than 1 for any other angle. It is thus a judgement of orientation and not magnitude: two vectors with the same orientation have a cosine similarity of 1, two vectors at 90° have a similarity of 0, and two vectors diametrically opposed have a similarity of -1, independent of their magnitude. It is useful as the similarities are represented mainly on the scale between 1 and 0, so for other manipulation it is normalized.
I coded two recommendation systems as one takes one movie for a user and then estimates five most similar movies, however that did not seem as too personalized, so the second recommendation system takes all movies that a user rated above his/her average and according to their genres and tags computes the five most similar movies.
For the recommendation system I used again Tfidf vectorizer as it returns the proportion that each token is represented in the collection of movie tags and genres. Then I computed the cosine similarity between the user's movie and the rest of of the movies (genres, tags, and mean ratings). In Sklearn cosine similarity, or the cosine kernel, processes similarity as the normalized dot product of features and target. Cosine similarity computes the cosine of the angle between the two vectors. The cosine of 0° is 1, and it is less than 1 for any other angle. It is thus a judgement of orientation and not magnitude: two vectors with the same orientation have a cosine similarity of 1, two vectors at 90° have a similarity of 0, and two vectors diametrically opposed have a similarity of -1, independent of their magnitude. It is useful as the similarities are represented mainly on the scale between 1 and 0, so for other manipulation it is normalized.
I coded two recommendation systems as one takes one movie for a user and then estimates five most similar movies, however that did not seem as too personalized, so the second recommendation system takes all movies that a user rated above his/her average and according to their genres and tags computes the five most similar movies.
So let's look what is recommends to a person who liked Boomerang (1992):
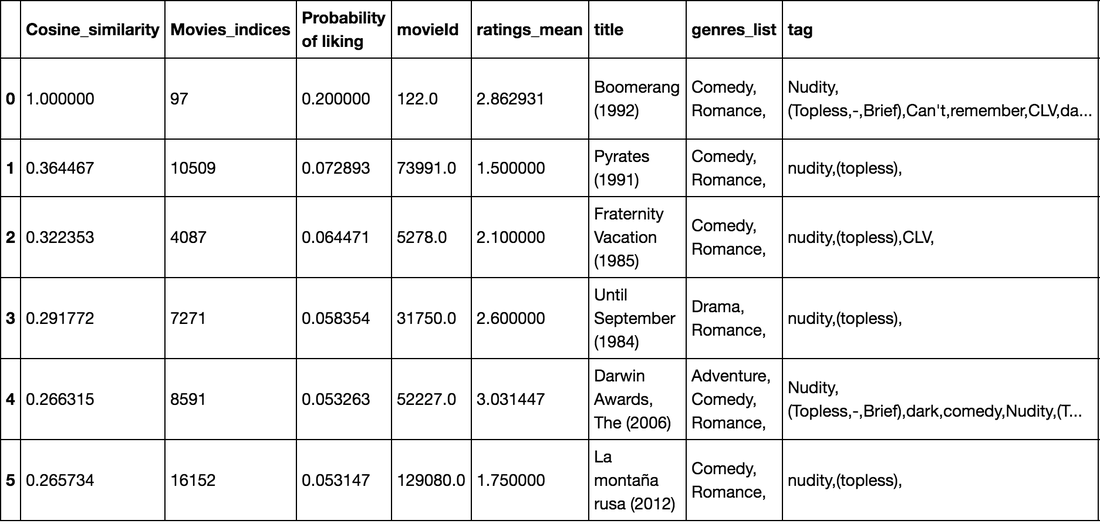
It looks pretty good with all the nudity and topless tags!
And what about more personalized one? That one is very hard to assess as users like many movies, but just for an example who it works:
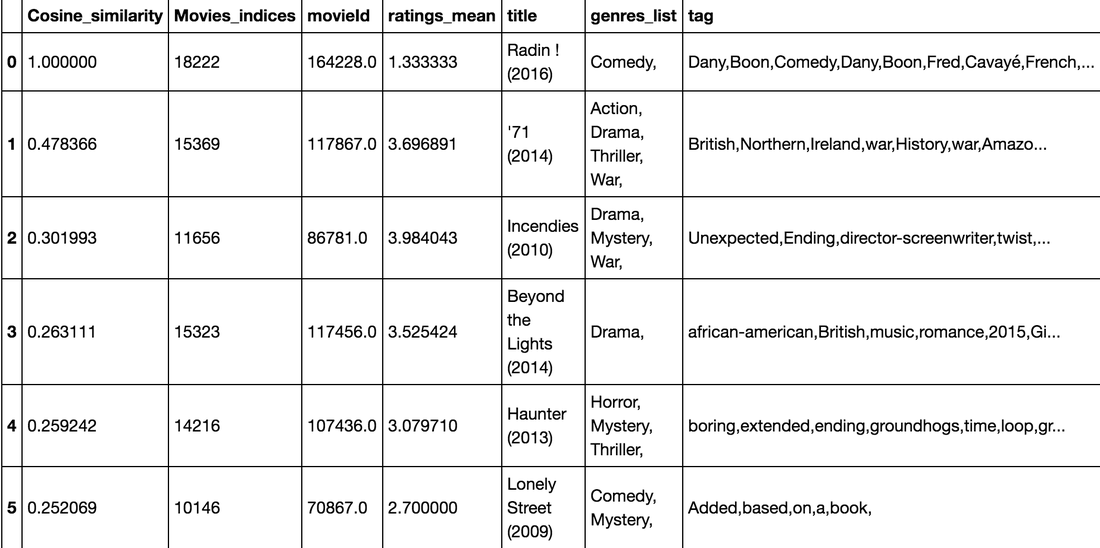
Conclusion:
It is not that easy to predict genre only from movie title. The next step should be to include synopsis or the tags used for recommendations. The situation is harder also because it is a multi-label problem, so getting the exact combination of genres is very hard. It can be a shout at the studios: 'Name your movies better and more according to the genre!' Some genres were doing better than other (horror as the best one and drama as the worst one). Also there is a space for tuning the model and trying diffent models like random forrest that could also handle OneVsRest. There is also alternative OneVsOne (takes pairs of classes), but this one is slower than one-vs-rest as there are more combinations.
The hardest part of the project was the assessment of the recommendation systems as the best way to do it is manually looking for user and what they rated and what are their recommendations. The recommendations for specific movie are quite exact as the tags and genres match. It is harder to say with the more general likings recommendations.
It would also be interesting to look deeper into the ratings, but the dataset is too large, so it would need to be handled in Spark for better performance.
My presentation and Technical report can be found here: https://github.com/katerinaC/DSI-SF-4-katerinaC/tree/master/Projects/Capstone/Movies
It is not that easy to predict genre only from movie title. The next step should be to include synopsis or the tags used for recommendations. The situation is harder also because it is a multi-label problem, so getting the exact combination of genres is very hard. It can be a shout at the studios: 'Name your movies better and more according to the genre!' Some genres were doing better than other (horror as the best one and drama as the worst one). Also there is a space for tuning the model and trying diffent models like random forrest that could also handle OneVsRest. There is also alternative OneVsOne (takes pairs of classes), but this one is slower than one-vs-rest as there are more combinations.
The hardest part of the project was the assessment of the recommendation systems as the best way to do it is manually looking for user and what they rated and what are their recommendations. The recommendations for specific movie are quite exact as the tags and genres match. It is harder to say with the more general likings recommendations.
It would also be interesting to look deeper into the ratings, but the dataset is too large, so it would need to be handled in Spark for better performance.
My presentation and Technical report can be found here: https://github.com/katerinaC/DSI-SF-4-katerinaC/tree/master/Projects/Capstone/Movies